How to Use left join in Spark Scala
How to Use left join in Spark Scala with Examples
The join function in Apache Spark is used to combine two DataFrames based on common columns or keys. This operation is essential for data integration and analysis tasks. In this tutorial, we will cover how to perform left join in Spark using Scala with practical examples.
1. Creating Sample DataFrames
Employee Table
| id | name | age |
|---|---|---|
| 1 | John | 28 |
| 2 | Alice | 34 |
| 4 | Bob | 23 |
Salary Table
| id | salary |
|---|---|
| 1 | 50000 |
| 2 | 60000 |
//please use below line else toDF will show error
import sparkSession.implicits._
val employeeData = Seq(
(1, "rahul", 28),
(2, "anil", 34),
(4, "Raju", 23)
)
val salaryData = Seq(
(1, 50000),
(2, 60000)
)
val employeeDF = employeeData.toDF("id", "name", "age")
val salaryDF = salaryData.toDF("id", "salary")
2. Importing Necessary Libraries
Before we can use left join, we need to import the necessary libraries:
import org.apache.spark.sql.{SparkSession}
3. left join : If Joining column name is same in both DataFrames
Now that we have our DataFrames, we can combine them using the join function:
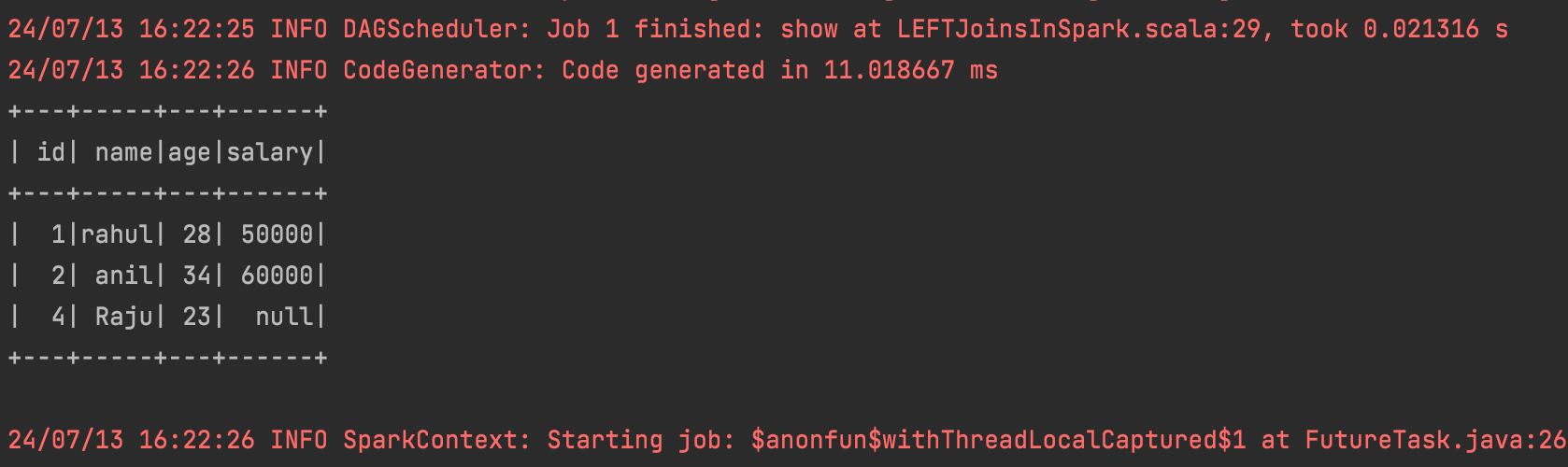
val leftJoinDF1 = employeeDF.join(salaryDF,Seq("id"),"left")
leftJoinDF1.show()
3.left Join: Multiple column name are same in both DataFrames
This approach is particularly useful for controlling column selection when dealing with multiple common columns across both DataFrames.
val leftJoinDF2 = employeeDF.as("emp").join(salaryDF.as("sal"),
employeeDF.col("id")===salaryDF.col("id"),"left")
.select("emp.id","emp.name","emp.age","sal.salary")
leftJoinDF2.show()
Complete Code
import org.apache.spark.sql.SparkSession
object LeftJoinsInSpark {
def main(args: Array[String]): Unit = {
val sparkSession = SparkSession
.builder()
.appName("Use union in scala spark")
.master("local")
.getOrCreate()
//please use below line else toDF will show error
import sparkSession.implicits._
val employeeData = Seq(
(1, "rahul", 28),
(2, "anil", 34),
(4, "Raju", 23)
)
val salaryData = Seq(
(1, 50000),
(2, 60000)
)
val employeeDF = employeeData.toDF("id", "name", "age")
val salaryDF = salaryData.toDF("id", "salary")
//style 1 use this if only joining column name is same
val innerJoinDF1 = employeeDF.join(salaryDF,Seq("id"),"left")
innerJoinDF1.show()
//style 2 - use this if column names are same other then joining column
val innerJoinDF2 = employeeDF.as("emp").join(salaryDF.as("sal"),
employeeDF.col("id")===salaryDF.col("id"),"left")
.select("emp.id","emp.name","emp.age","sal.salary")
innerJoinDF2.show()
}
}