Using the flatMap Function in PySpark - Comprehensive Guide
Understanding the flatMap Function in PySpark
The flatMap function in PySpark is a powerful transformation that returns a new RDD by applying a function to all elements of the original RDD and then flattening the results. This function is particularly useful when dealing with nested structures and when you need to perform operations that yield multiple outputs from a single input.
What is the flatMap Function in PySpark?
The flatMap function in PySpark is similar to the map function, but with a key difference: while map returns a single value for each input element, flatMap can return multiple values, which are then flattened into a single list. This makes it ideal for scenarios where you want to break down a single element into multiple parts.
Using the flatMap Function in PySpark
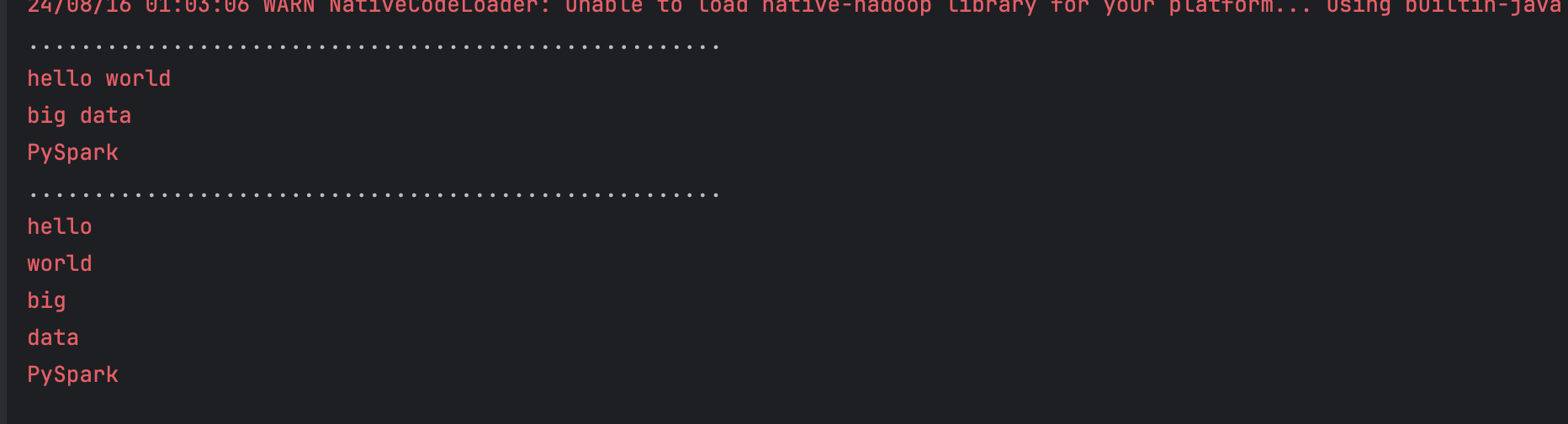
Here’s a basic example of how to use the flatMap function:
#Example of using flatMap to flatten list
from pyspark.sql import SparkSession
spark_session=SparkSession.builder.master("local").appName("pyspark flatmap function with example").getOrCreate();
#simple_list
data = ["hello world", "big data", "PySpark"]
rdd = spark_session.sparkContext.parallelize(data)
print(".....................................................")
rdd.foreach(lambda data:print(data))
print(".....................................................")
flat_mapped_rdd = rdd.flatMap(lambda line: line.split(" "))
flat_mapped_rdd.foreach(lambda data:print(data))
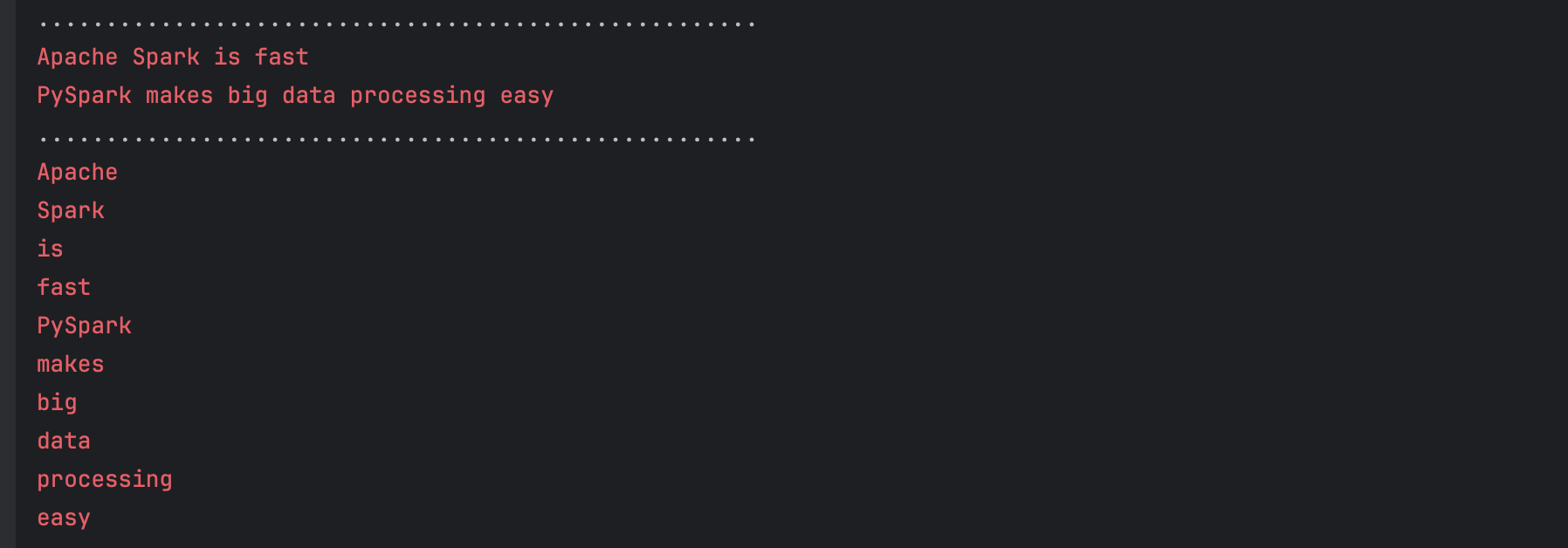
Real-World Example: Splitting Sentences into Words
Imagine you have a dataset of sentences, and you want to break each sentence down into individual words for further analysis. You can use the flatMap function to split each sentence into words and flatten the result into a single list of words:
# Example of using flatMap to flatten nested lists
from pyspark.sql import SparkSession
spark_session=SparkSession.builder.master("local").appName("pyspark flatmap function with example").getOrCreate();
#simple_list
sentences = ["Apache Spark is fast", "PySpark makes big data processing easy"]
rdd = spark_session.sparkContext.parallelize(sentences)
print(".....................................................")
rdd.foreach(lambda data:print(data))
print(".....................................................")
flat_mapped_rdd = rdd.flatMap(lambda line: line.split(" "))
flat_mapped_rdd.foreach(lambda data:print(data))
Performance Considerations
While the flatMap function can be incredibly useful, it's important to consider the size of the output it produces. Since flatMap can generate a large number of elements, it may lead to significant increases in data size, which could impact performance. Always consider the downstream processing when using flatMap and apply any necessary filtering to manage data volume effectively.
Conclusion
The flatMap function is a versatile tool in PySpark, enabling the transformation of complex data structures into simpler, flattened forms. Its ability to generate multiple outputs from a single input makes it indispensable in many data processing workflows, especially when working with nested data.