How to Use dropDuplicates in PySpark - Removing Duplicates
Using dropDuplicates in PySpark
Removing duplicate rows is a crucial step in data processing to maintain data integrity. In Apache PySpark, the dropDuplicates function provides a straightforward method to eliminate duplicate entries from a DataFrame. This tutorial will delve into the dropDuplicates function, showcasing how to use it effectively with practical examples. Learn how to apply this function to specific columns or entire DataFrames, ensuring your data remains clean and reliable.
Sample Data
| Category | Item | Quantity | Price |
|---|---|---|---|
| Fruit | Apple | 10 | 1.5 |
| Fruit | Apple | 10 | 1.5 |
| Vegetable | Carrot | 15 | 0.7 |
| Vegetable | Potato | 25 | 0.3 |
1. Importing Necessary Libraries
Before we can use dropDuplicates, we need to import the necessary libraries:
from pyspark.sql import SparkSession from pyspark.sql.types import DoubleType, IntegerType, StringType, StructField, StructType from pyspark.sql import Row
2. Creating a Sample DataFrame
# Initialize SparkSession
spark = SparkSession.builder \
.appName("Remove duplicates from a PySpark DataFrame") \
.master("local") \
.getOrCreate()
# Define the schema
schema = StructType([
StructField("category", StringType(), True),
StructField("item", StringType(), True),
StructField("quantity", IntegerType(), True),
StructField("price", DoubleType(), True)
])
# Create the data
data = [
Row("Fruit", "Apple", 10, 1.5),
Row("Fruit", "Apple", 10, 1.5),
Row("Vegetable", "Carrot", 15, 0.7),
Row("Vegetable", "Potato", 25, 0.3)
]
# Create the DataFrame
rdd = spark.sparkContext.parallelize(data)
3. Using dropDuplicates to Remove Duplicate Rows
To remove duplicate rows in a DataFrame, use the dropDuplicates function. This function can be used without any arguments to remove fully duplicate rows:
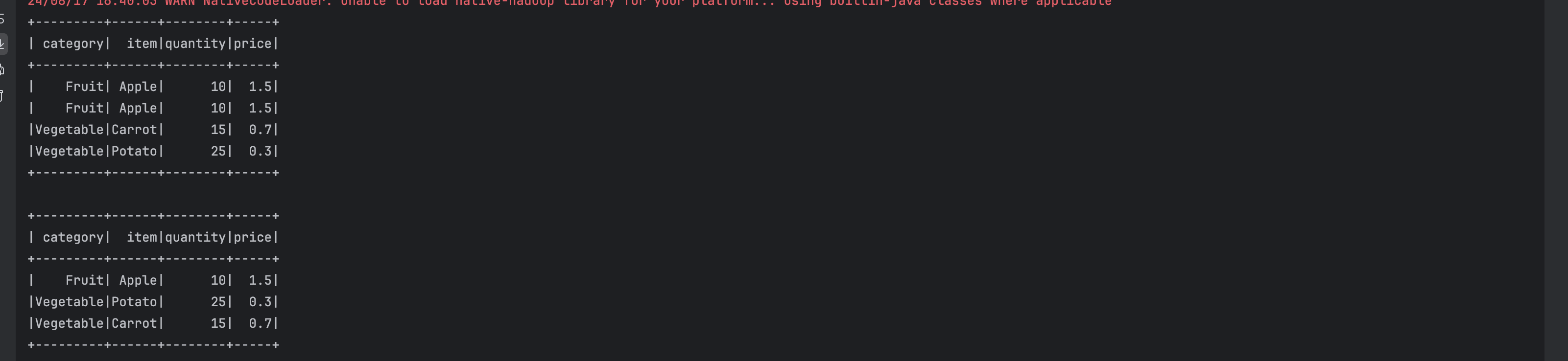
unique_df = df.dropDuplicates() unique_df.show()
4. Removing Duplicates Based on Specific Columns
You can also specify columns to consider for identifying duplicates. For example, to remove rows that have the same "item" and "quantity" values:
unique_df = df.dropDuplicates("item", "quantity")
unique_df.show()
5.Complete code
You can combine dropDuplicates with other transformations for more complex data processing. Here is an example:
from pyspark.sql import SparkSession
from pyspark.sql.types import DoubleType, IntegerType, StringType, StructField, StructType
from pyspark.sql import Row
# Initialize SparkSession
spark = SparkSession.builder \
.appName("Remove duplicates from a PySpark DataFrame") \
.master("local") \
.getOrCreate()
# Define the schema
schema = StructType([
StructField("category", StringType(), True),
StructField("item", StringType(), True),
StructField("quantity", IntegerType(), True),
StructField("price", DoubleType(), True)
])
# Create the data
data = [
Row("Fruit", "Apple", 10, 1.5),
Row("Fruit", "Apple", 10, 1.5),
Row("Vegetable", "Carrot", 15, 0.7),
Row("Vegetable", "Potato", 25, 0.3)
]
# Create the DataFrame
rdd = spark.sparkContext.parallelize(data)
df = spark.createDataFrame(rdd, schema)
df.show()
# Remove duplicates
unique_df = df.dropDuplicates()
# Show the result
unique_df.show()
Output
In this tutorial, we have seen how to use the dropDuplicates function in PySpark with to remove duplicate rows from a DataFrame. This function is very useful for data cleaning and preparation tasks. For more advanced operations, consider combining it with other DataFrame transformations.