How to Use inner join in PySpark
How to Use inner join in PySpark with Examples
The join function inPySpark is a powerful tool used to merge two DataFrames based on shared columns or keys. This operation is crucial for data integration and analysis. In this tutorial, we’ll explore how to perform an inner join in PySpark, providing practical examples to guide you through the process.
1. Creating Sample DataFrames
Employee Table
| id | name | age |
|---|---|---|
| 1 | John | 28 |
| 2 | Alice | 34 |
| 4 | Bob | 23 |
Salary Table
| id | salary |
|---|---|
| 1 | 50000 |
| 2 | 60000 |
| 4 | 70000 |
# Create employee data employee_data = [ (1, "rahul", 28), (2, "anil", 34), (4, "Raju", 23) ] # Create salary data salary_data = [ (1, 50000), (2, 60000), (4, 70000) ] # Create DataFrames employee_df = spark.createDataFrame(employee_data, ["id", "name", "age"]) salary_df = spark.createDataFrame(salary_data, ["id", "salary"])
2. Importing Necessary Libraries
Before we can use inner join, we need to import the necessary libraries:
from pyspark.sql import SparkSession from pyspark.sql.functions import col
3. Inner join : If Joining column name is same in bothDataFrames
Now that we have our DataFrames, we can combine them using the join function:
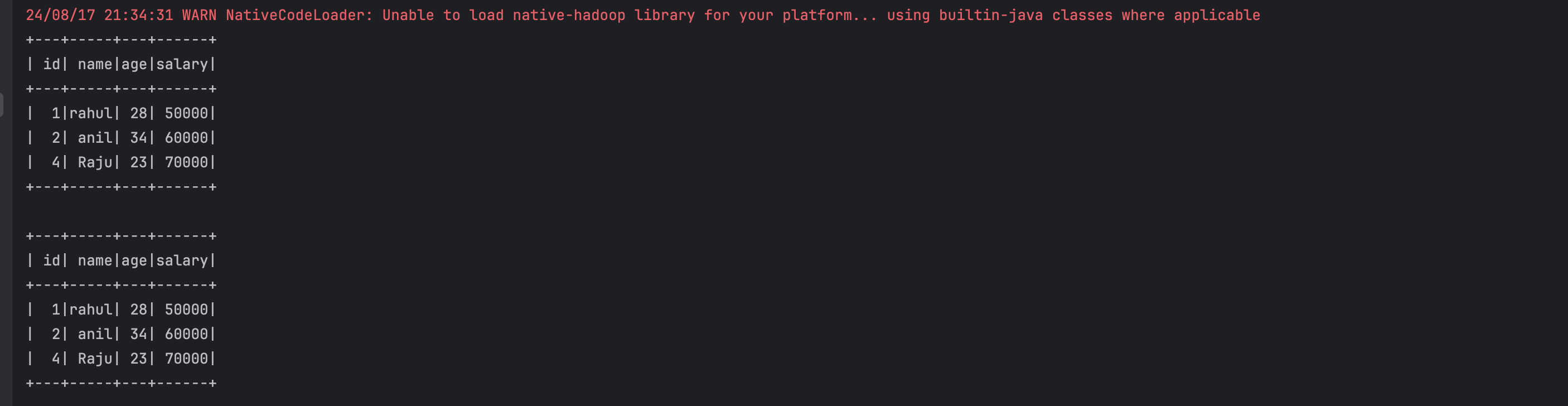
# Style 1: Join using the common column name inner_join_df1 = employee_df.join(salary_df, ["id"], "inner") inner_join_df1.show()
3.Inner Join: Multiple column name are same in both DataFrames
This approach is particularly useful for controlling column selection when dealing with multiple common columns across both DataFrames.
# Style 2: Join using aliases (useful when column names are the same except the joining column)
inner_join_df2 = employee_df.alias("emp").join(
salary_df.alias("sal"),
col("emp.id") == col("sal.id"),
"inner"
).select("emp.id", "emp.name", "emp.age", "sal.salary")
Complete Code
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
# Initialize SparkSession
spark = SparkSession.builder \
.appName("Use join in PySpark") \
.master("local") \
.getOrCreate()
# Create employee data
employee_data = [
(1, "rahul", 28),
(2, "anil", 34),
(4, "Raju", 23)
]
# Create salary data
salary_data = [
(1, 50000),
(2, 60000),
(4, 70000)
]
# Create DataFrames
employee_df = spark.createDataFrame(employee_data, ["id", "name", "age"])
salary_df = spark.createDataFrame(salary_data, ["id", "salary"])
# Style 1: Join using the common column name
inner_join_df1 = employee_df.join(salary_df, ["id"], "inner")
inner_join_df1.show()
# Style 2: Join using aliases (useful when column names are the same except the joining column)
inner_join_df2 = employee_df.alias("emp").join(
salary_df.alias("sal"),
col("emp.id") == col("sal.id"),
"inner"
).select("emp.id", "emp.name", "emp.age", "sal.salary")
inner_join_df2.show()
# Stop the SparkSession
spark.stop()